Loss Function similarity
Tips
post blow was copied from MSiam
Table of Contents
- Siamese and Triplet Networks
- Cross Entropy Loss
- Contrastive Loss
- Triplet Loss
Siamese and Triplet Networks
Metric learning methods have the advantage that they rapidly learn novel concepts without retraining. A siamese network consists of two twin networks with shared weights, similarly a triplet network contains three copies of the network with shared weights. We are going to discuss the different loss functions used to train these:
Cross Entropy Loss
One of the earliest attempts that was designed mainly for few shot learning using siamese networks was by Koch [6]. It formulated the few shot learning problem as a verification task. A siamese network is used and a weighted L1 distance function is learned between their embeddings. This is done by applying L1 distance on the output embeddings then adding one fully connected layer to learn the weighted distance. The loss function used in the paper is a regularized cross entropy, where the main aim is to drive similar samples to predict 1, and 0 otherwise.
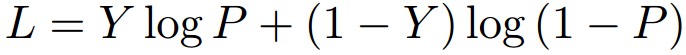
Contrastive Loss
One approach is to learn a mapping from inputs to vectors in an embedding space where the inputs of the same class are closer than those of different classes. Once the mapping is learned, at test time a nearest neighbors method can be used for classification for new classes that are unseen. A siamese network is trained with the output features fed to a Contrastive Loss [4]:
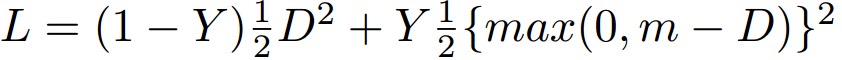
Y label is 0 for similar class samples, 1 for dissimilar, and D is the euclidean distance. So the loss will decrease the distance D when the samples are from the same class, on the other hand when they are dissimilar it will try to increase D with a certain margin m. The margin purpose is to neglect samples that have larger distance than m, since we only want to focus on dissimilar samples that appear to be close.
Triplet Loss
A better extension on the contrastive loss idea is to use a triplet network with triplet loss [5]. The triplet network inspiring from the siamese networks will have three copies of the network with shared weights. The input contains an anchor sample, a positive sample and a negative sample. The three output embeddings are then fed to the triplet loss [5]:
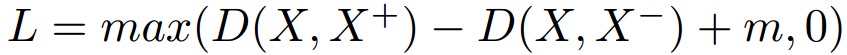
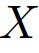 is the anchor sample,
is the anchor sample, 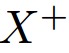 is the positive sample,
is the positive sample, 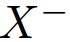 is the negative sample, D is the distance function and m is the margin. The loss is decreasing the distance between the anchor and its positive sample while at the same time increasing its distance to the negative sample.
is the negative sample, D is the distance function and m is the margin. The loss is decreasing the distance between the anchor and its positive sample while at the same time increasing its distance to the negative sample.
Summary
To sum it up there are three things to think of when desiging your method :
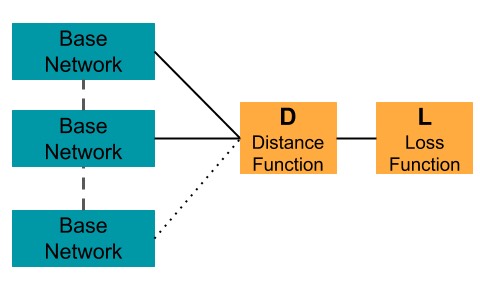
- The base network architecture used in the siamese or triplet network.
- The distance function applied on the output embeddings:
- L2 distance (Euclidean)
- L1 distance
- Weighted L1 distance
- Cosine distance
- The loss function:
- Contrastive Loss
- Triplet Loss
- Cross Entropy
References
[4] Hadsell, Raia, Sumit Chopra, and Yann LeCun. “Dimensionality reduction by learning an invariant mapping.” null. IEEE, 2006.
[5] Hoffer, Elad, and Nir Ailon. “Deep metric learning using triplet network.” International Workshop on Similarity-Based Pattern Recognition. Springer, Cham, 2015.
[6] Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. “Siamese neural networks for one-shot image recognition.” ICML Deep Learning Workshop. Vol. 2. 2015.